

Instagram is the largest photo sharing social media platform with 500 million monthly active users, and 95 million pictures and videos uploaded on Instagram everyday. It has a huge amount of data and huge potential. This guide will help you view Instagram as a source of data and not just a platform, and how to use it as a developer for your projects.
About API and Tools
Instagram has an official API but it is outdated and is currently very limited in things you can do with it. So in this guide I will use LevPasha’s Unofficial Instagram API, which supports all major features like like, follow, upload photo and video, etc! It is written in Python, but I will focus only on the data side.
I recommend using Jupyter notebooks and IPython. Normal python will work fine, but you may not have features like displaying the images
Installation
You can install the library using
pip this way:python -m pip install -e git+https://github.com/LevPasha/Instagram-API-python.git#egg=InstagramAPI
You will need
ffmpeg if you don't have it. To install it on Linux:sudo apt-get install ffmpeg
For Windows, run this in your Python interpreter:
import imageio imageio.plugins.ffmpeg.download()
Logging in to Instagram Using the API
from InstagramAPI import InstagramAPI username="YOURUSERNAME" InstagramAPI = InstagramAPI(username, "YOURPASSWORD") InstagramAPI.login()
If successful, you should receive a "Login Success" message.
Simple Request
With that out of the way let's get started with our first request:
InstagramAPI.getProfileData() result = InstagramAPI.LastJson
{u'status': u'ok',
u'user': {u'biography': u'',
u'birthday': None,
u'country_code': 20,
u'email': aaa@hotmail.com',
u'external_url': u'',
u'full_name': u'Nour Galaby',
u'gender': 1,
u'has_anonymous_profile_picture': False,
u'hd_profile_pic_url_info': {u'height': 1080,
u'url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-1aaa7448121591_1aa.jpg',
u'width': 1080},
u'hd_profile_pic_versions': [{u'height': 320,
u'url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-19/s320x320/19aa23237_4337448121591_195310aaa32_a.jpg',
u'width': 320},
{u'height': 640,
u'url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-19/s640x640/19623237_45581744812153_44_a.jpg',
u'width': 640}],
u'is_private': True,
u'is_verified': False,
u'national_number': 122,
u'phone_number': u'+201220',
u'pk': 22412229,
u'profile_pic_id': u'1550239680720880455_22',
u'profile_pic_url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-19/s150x150/19623237_455817448121591_195310166162_a.jpg',
u'show_conversion_edit_entry': False,
u'username': u'nourgalaby'}}
As you can see, the result is in JSON format, containing all of the requested data.
You can access it in the normal key/value way. For example:
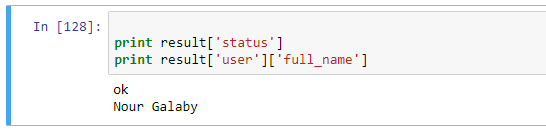
You can use any advance viewing tool (Notepad++) to view the JSON and explore it.
Get and View Instagram Timeline
Now let's do something more interesting. We will request the last posts in the timeline and view them in our notebook.
With this line you can get the timeline:
InstagramAPI.timelineFeed()
And similar to the previous request, we will use LastJson() to view the result. By inspecting the resulting JSON, we can see that it holds a list in a key called 'items.' Each element in that list holds information about a specific post in the timeline, including such elements as:
- [text] - holds the text value for the caption written under the post, including hashtags
- [likes] - the number of likes that a post has
- [created_at] - date post created
- [comments] - post comments
- [image_versions] - holds links to the actual JPG file, which we will use to display it on our Jupyter notebook
Functions
Get_posts_from_list() and Get_url() will iterate over the list of posts and for each post will find the URL and append it to our empty list:
After it's done, we should have a list of URLs like the following:

To view the images, we can use the
Ipython.display module as follows:
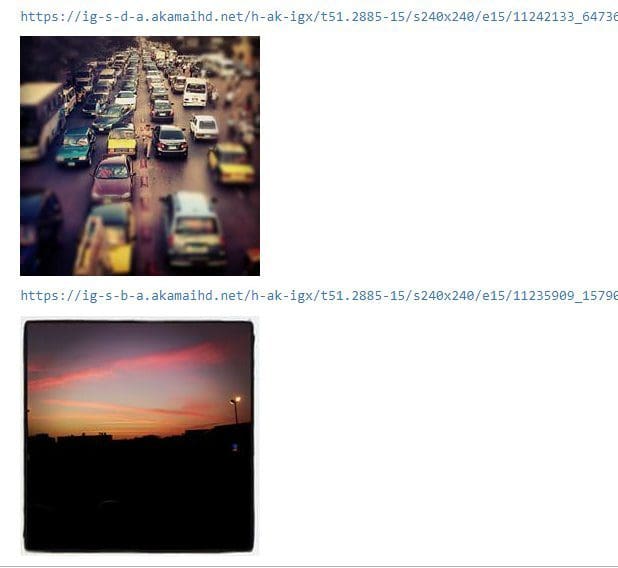
Viewing images in a notebook is very useful and we will use those functions later to view our results, as you will see.
Get Your Most Liked Posts
Now we know how to make a basic request, but what if we want to get more complex requests? Here we will do something similar: we will get our most liked posts. In order to do that, first we need to get all posts in your user profile, and then sort them by number of likes:
Get All User Posts
In order to get all the posts we will use the
next_max_id and more_avialable values to iterate over our list of results:import time
myposts=[]
has_more_posts = True
max_id=""
while has_more_posts:
InstagramAPI.getSelfUserFeed(maxid=max_id)
if InstagramAPI.LastJson['more_available'] is not True:
has_more_posts = False #stop condition
print "stopped"
max_id = InstagramAPI.LastJson.get('next_max_id','')
myposts.extend(InstagramAPI.LastJson['items']) #merge lists
time.sleep(2) # Slows the script down to avoid flooding the servers
print len(myposts)
v
Hello


























{kind=link}
{kind=link}